
紙の原稿があり、文字入力してテキストデータを作らなければならない場合がよくあります。
できれば半自動でテキストデータ化して時間を節約したいところです。
ここではAdobe® Acrobat®を使って文字原稿を半自動でテキストデータ化する方法をご紹介します。
紙の文字原稿を半自動でテキストデータ化するために必要な道具類
このページでは以下の道具を使用します。
- スキャナー
- Adobe® Acrobat®かWondershare PDFelements
スキャナーの例
紙の文書を手早くスキャンするなら、ドキュメントスキャナーが楽でしょう。
ドキュメントスキャナーは中古市場にも多数あるので、まずは良い中古品を探すと良いでしょう。新品を購入するよりも環境負荷を低く抑えられます。

ハードオフ

Acrobat


PDFelements

紙の文字原稿をテキストデータ化する 具体的な手順
手順1 原稿をスキャニングする
紙の原稿をスキャナーでパソコンに取り込みます。
スキャナーのユーティリティーソフトを使用して、文書に適したモード、線画に適したモードなどで取り込みます。
文字だけの原稿の場合
黒い字だけの原稿の場合
紙の原稿が黒い文字だけの原稿なら、線画のモード、スキャン解像度300〜600dpi程度、が適しています。
スキャン解像度は字の大きさにより調節します。
それほど小さい字がなければ300dpi、結構小さい字があれば600dpiにするなどします。
試しに1枚スキャンして、文字がきちんと読めるようにスキャンされているか確認するとよいでしょう。
色の付いた字がある場合
文字だけの原稿ではあるものの、黒だけでなく色の付いた文字もある場合は、文書のモードなどが適しています。
スキャン解像度は字の大きさにより調節します。
それほど小さい字がなければ300dpi、結構小さい字があれば600dpiにするなどします。
この場合も、試しに1枚スキャンして、文字がきちんと読めるようにスキャンされているか確認するとよいでしょう。
写真など文字以外のものがある原稿の場合
写真やグラフなど文字以外のものがある原稿の場合は以下のようにします。
文字は黒い文字だけの場合
文字の部分は黒い文字だけなら、線画のモード、スキャン解像度300〜600dpi程度、が適しています。
写真やグラフはまともにスキャンされませんが、欲しいのは文字の部分だけなので問題ありません。
文字の下地に色が入っている、色つきの文字がある、などの場合
色が塗られた上に文字があったり、文字に色が付いているなど、白地に黒い文字という場所だけではない場合、文書のモード、スキャン解像度300〜600dpi程度、が適しています。
スキャン解像度は字の大きさにより調節します。
それほど小さい字がなければ300dpi、結構小さい字があれば600dpiにするなどします。
この場合も、試しに1枚スキャンして、文字がきちんと読めるようにスキャンされているか確認するとよいでしょう。
手順2 スキャン済み画像をPDFファイルにする
スキャンした画像をPDFファイルにします。
※スキャン結果がすでにPDFで保存されている場合は、この操作は不要です。
Acrobatで[ファイル>作成>ファイルからPDF]と進みます。
スキャンした画像データを選んで、「開く」をクリックします。
画像データがPDFファイルになります。
手順3 Acrobatで文字認識をする
[表示>ツール>スキャン補正>開く]と進み、スキャン補正に関するメニューを表示します。
メニューのバーから「テキスト 認識 > このファイル内」を選びます。
「テキスト認識」をクリックします。
手順4 テキストをコピーして使う
目には見えませんが、以上の操作でPDF内にテキストデータが作成されました。
選択ツールで文字の部分をなぞって選択し、コピーすればテキストをコピーできます。
あとはテキストエディタなり、その他のソフトなりにペーストして使用します。
手順5 文字校正をする
たいていの場合、Acrobatが文字認識に失敗している箇所が出てきます。
ペーストしたテキストを確認し、文字の間違いを修正します。
Acrobatからテキストデータを取り出す方法は色々ある
Acrobatでテキストデータを作り出した後、コピーペーストではなくメニューからテキストデータとして保存することもできます。
ただ、原稿がレイアウトの入り組んだ文書の場合などは、どの部分のテキストがテキストデータの何行目あたりにくるか判断できません。
そのような場合は単純にコピー&ペーストで作業した方が良いでしょう。
スキャン文書の文字認識はAcrobat以外のソフトでも可能
画像データのテキスト部分を認識して文字データに変換するOCR(Optical Character Reader)の機能を持つソフトはAcrobat以外にもあります。
Wondershare PDFelement(PDFエレメント)を使ってテキストデータ化する作業
Wondershare PDFelement(PDFエレメント)を使ってスキャン画像からテキストデータを作れます。
PDFelements
前述した手順で紙文書をスキャンし、PDFまたはJPGやTIFF画像で保存します。
スキャンしたデータをPDFelementで開きます。
PDFの場合は「開く」から進んでファイルを開きます。
JPGやTIFFなどの画像データの場合は「PDF作成」へ進んでファイルを開くとPDFに変換して開かれます。
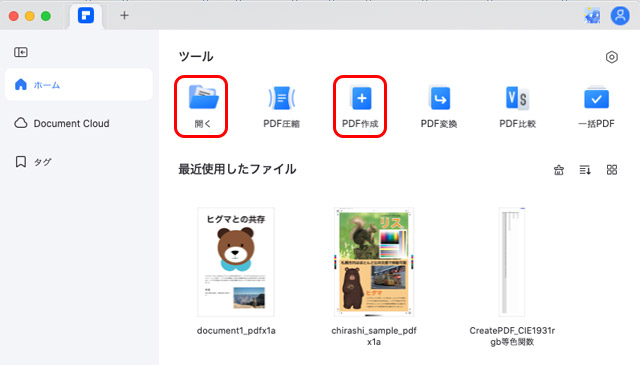
WonderShare PDFelementの画面
「PDF作成」に進みTIFF画像を開いた例
メニューから[ツール>OCRテキスト認識]と進みます。
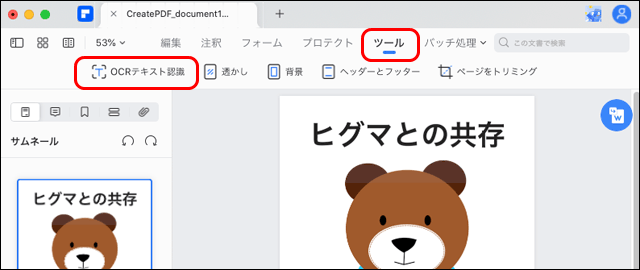
「OCRテキスト認識」へ進む
検索可能なPDFを作ってテキストをコピーして使う場合
「OCRテキスト認識」の画面で種類に「検索可能な画像」を選択します。
「OCRを実行します」をクリックしてテキストデータ化する作業を実行します。
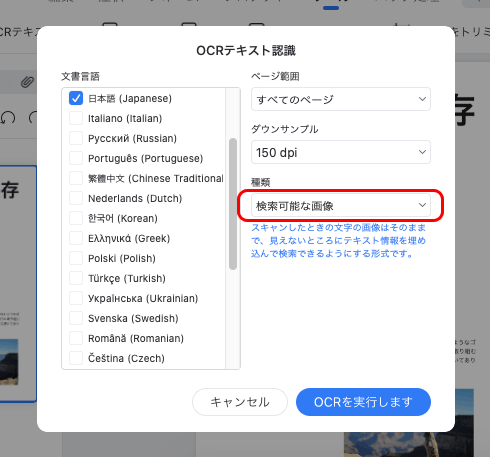
「OCRテキスト認識」の画面
処理が終了したら、「開く」をクリックするとテキストデータが埋め込まれたPDFが別ファイルとして開かれます。
「開く」をクリック
開かれたPDFにはテキストデータが埋め込まれているので、文字の部分をカーソルで選択してコピーしてどこかに貼り付けてテキストデータとして使えます。
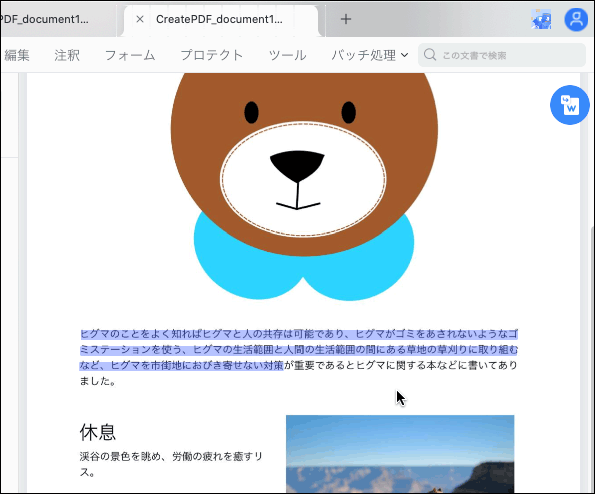
OCR作業後のPDF上の文字を選択した例
PDFをWordファイルに変換してテキストデータを使う場合
「OCRテキスト認識」の画面で種類に「編集可能なテキスト」を選択します。
「OCRを実行します」をクリックしてテキストデータ化する作業を実行します。
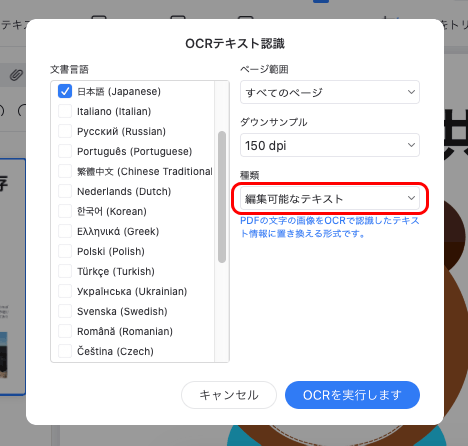
「OCRテキスト認識」の画面で「編集可能なテキスト」を選択
処理が終了したら、「開く」をクリックすると画像上の文字がテキストデータに置き換わったPDFが別ファイルとして開かれます。
「開く」をクリック
右上にある「PDFからWordへ」のアイコンボタンをクリックするとPDFファイルがWordファイルに変換されます。ファイル保存の画面が表示されるのでパソコン内のどこかへ保存します。
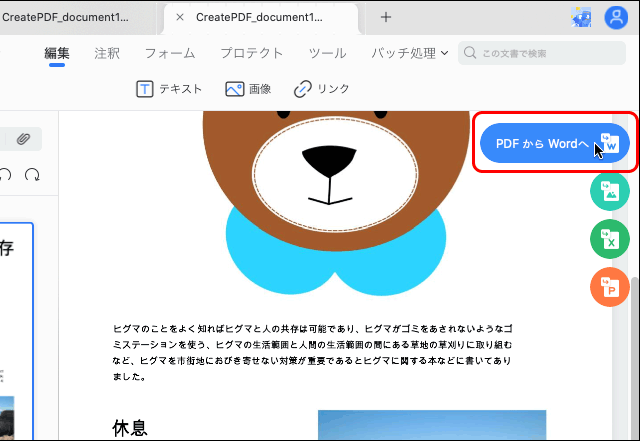
「PDFからWordへ」のアイコンボタンをクリック
保存したWordファイルを開き、テキストデータを選択して利用できます。

保存したWordファイルをMacの「Pages」で開いてテキストを選択した例
その他のソフト
ScanSnapのユーティリティーソフトやドキュワークスでも文字認識はできます。
以上、紙の原稿を、Adobe Acrobatを使って半自動でテキストデータ化する方法をご紹介しました。
参考記事

PDF編集ソフト
Acrobat
PDFelements
文書向けスキャナー
ドキュメントスキャナーは中古市場にも多数あるので、まずは良い中古品を探すと良いでしょう。新品を購入するよりも環境負荷を低く抑えられます。
ハードオフ

