
ドキュメントスキャナー「ScanSnap」で紙の書類をPDFなどにして電子化できます。
以前のScanSnapでは高い品質で文書をPDF化するために原稿の種類ごとに設定を変更する必要がありましたが、最近のScanSnapは原稿の種類によらず自動判別でPDF化できるようになりました。
ScanSnapでカラー文書、グレースケールの文書、文字・線画のみの文書、それらが混在している冊子など、全てスキャナーの自動判別でPDF化する方法の一例をご紹介します。
使うScanSnapとユーティリティーソフト
ScanSnapのユーティリティーソフト「ScanSnap Home」を使ってスキャニングします。
使ったScanSnap本体はiX1500という機種です。
このページで紹介する内容は結局のところユーティリティーソフトの設定が全てなので、ユーティリティーソフトが「ScanSnap Home」であればスキャナー本体は別の機種でも設定自体はおそらく同じです。
環境負荷低減のため新品の購入を避けたかったので、ハードオフのオンラインストアでScanSnapを探し、札幌市内で在庫のあるハードオフの店舗を見つけ、JRと地下鉄で行って買ってきました。
ScanSnapの例

中古販売店


ScanSnapでカラー/グレー/文字・線画を自動判別でPDF化する設定の一例
1.設定のテンプレートを選ぶ
「ScanSnap Home」を起動し、「scan」というボタンをクリックします。
「ScanSnap Home」を起動し、「scan」をクリック
「ScanSnap Home – スキャン」の画面のプロファイルを追加するアイコンボタンをクリックします。

「ScanSnap Home – スキャン」の画面の、プロファイルを追加するアイコンボタンをクリック
「新規プロファイル追加」の画面の左のテンプレート一覧から「書類を保存」を選びます。
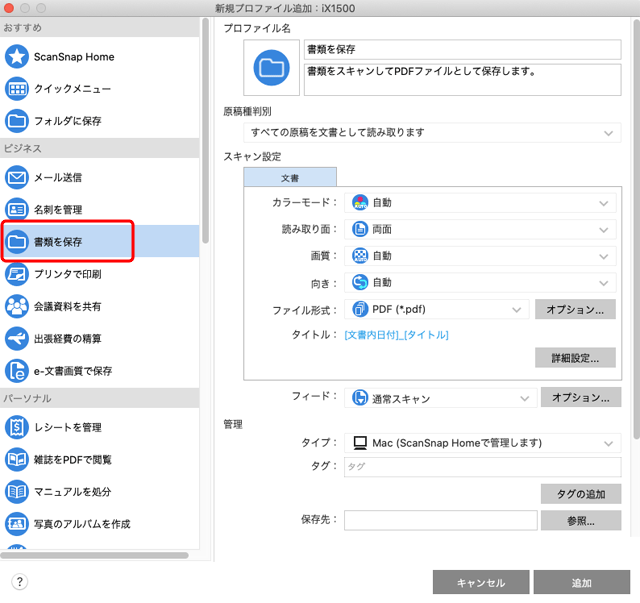
「新規プロファイル追加」の画面で「書類を保存」を選択
2.主要な項目の設定変更
主要な項目の設定を変更します。
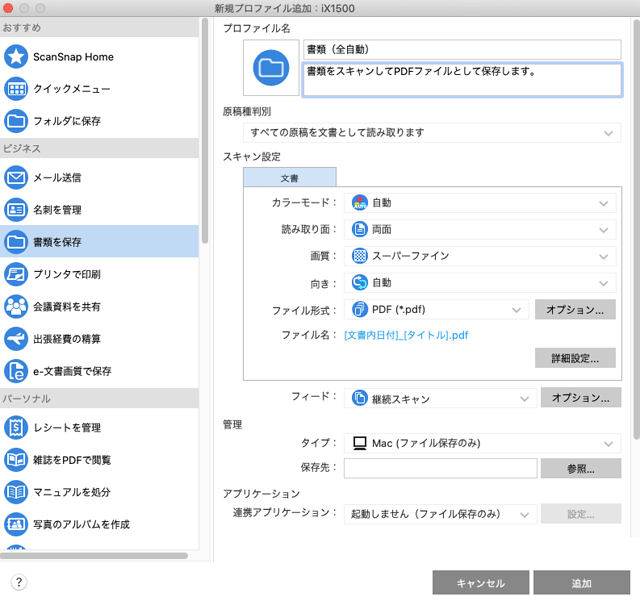
主な項目の設定を変更
プロファイル名
「プロファイル名」の欄で「書類(全自動)」なり別の名前なり、自分が好きな名前を付けます。
「プロファイル名」の設定欄の下の欄に、この設定が何のスキャン用か後から自分で分かりやすいよう説明文を付けられます。
原稿種判別
「原稿種判別」の設定を変更してもほとんど何も変わらないように見えますが、実際は他の設定項目の種類や選択肢の種類などが少し変化します。
「原稿種判別」は「すべての原稿を文書として読み取ります」にしておきます。
カラーモード
「カラーモード」はスキャナーに自動的に判断させたいので「自動」にします。
読み取り面
「読み取り面」は片面の書類も両面の書類も全てに対応させたいので「両面」にします。
画質
「画質」は文字が小さい文書や写真が入っている文書などどのような文書も無難にきれいにスキャンするため「スーパーファイン」にします。
向き
「向き」はスキャナーに自動で判断させたいので「自動」にします。
ファイル形式
PDFファイルにしたいので「ファイル形式」は「PDF(*.pdf)」を選びます。
フィード
「フィード」は「継続スキャン」にします。
「継続スキャン」にしておくと、例えば100ページの冊子をPDF化するような場合に紙が詰まらないよう20枚(40ページ分)をスキャンし、スキャンが終わるとスキャナーが次の原稿がセットされるまで待ってくれるの次の20枚をセットしてスキャンを続行し、すべてスキャニングが終わったところでPDFを作成、というように大量のページを分けてスキャンでき、スキャナーに急かされることもないので便利です。
管理 – タイプ/保存先
「管理」の「タイプ」はMacのパソコンの場合なら「Mac(ファイル保存のみ)」にします。
「保存先」は自分のパソコンでスキャン済みPDFを保存したいフォルダを指定しておきます。
このように設定しておくと、ScanSnapでスキャンしてPDFにした後、ScanSnapのソフトを使わず自分でパソコン内で好きに管理できるので単純で手軽で便利です。
連携アプリケーション
ScanSnapで文書を電子化してPDFで保存したいだけなら「連携アプリケーション」欄は「起動しません(ファイル保存のみ)」にします。
Macを使っていて、スキャン後にPDFが保存されたフォルダが表示された方が便利なら「Finderで表示」を選ぶのも良いでしょう。
詳細の設定
ファイル形式
「ファイル形式」の「オプション」へ進み、「PDFオプション」を表示します。
「検索可能なPDFにします」にチェックを入れます。
これでスキャン後のPDFには文字情報が追加され、ただの画像のPDFではなく文字検索ができるPDFになります。
「すべての用紙を1つのPDFファイルにします」を選択します。
これで書類を1枚だけスキャンすればごく普通に1ページまたは2ページのPDFになり、100ページの冊子をスキャンすれば普通に100ページの1個のPDFになります。
「OK」をクリックします。
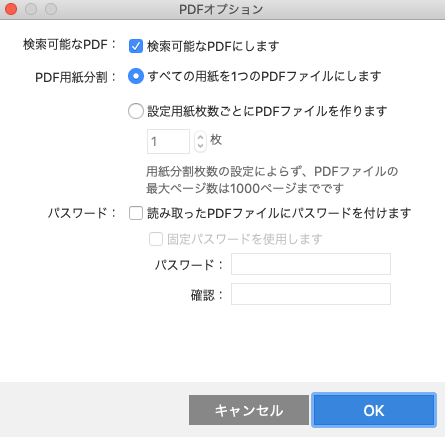
PDFオプション
スキャン設定の詳細設定
「ファイル名」の設定欄の右下にある「詳細設定」へ進みます。
「詳細設定」の画面の「ファイル名」のタブをクリックします。
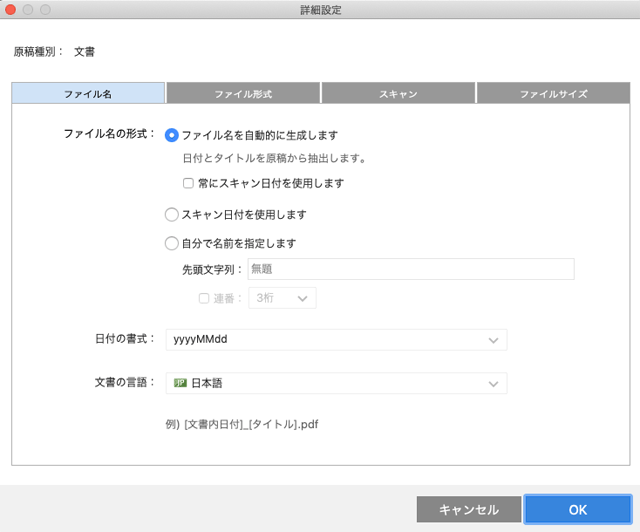
「詳細設定」の「ファイル名」タブ
「ファイル名の形式」で「ファイル名を自動的に生成します」を選べばスキャナーが文書の内容をもとにしてファイル名を付けてくれます。スキャナーが判断できなければスキャンした日付などが付きます。
「スキャン」のタブをクリックします。
「白紙ページを自動的に削除します」にチェックを入れると、例えば片面ペラの文書をスキャンしたときに両面がスキャンされますが白紙の面は削除され1ページのPDFができます。
さらにその右下の「オプション」へ進んでいくらかの項目を設定できます。私はそこはすべてオフのままにしています。
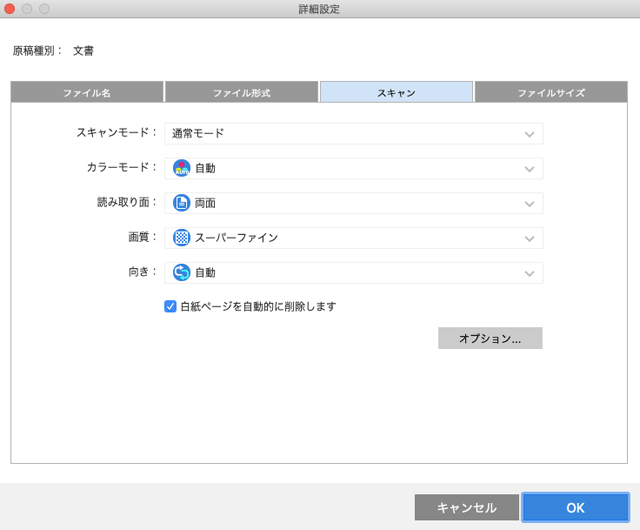
「詳細設定」の「スキャン」タブ
「ファイルサイズ」のタブをクリックします。
「圧縮率」を「中」にするとファイルサイズはある程度圧縮され、画質はそれほど劣化せずバランスが良いです。
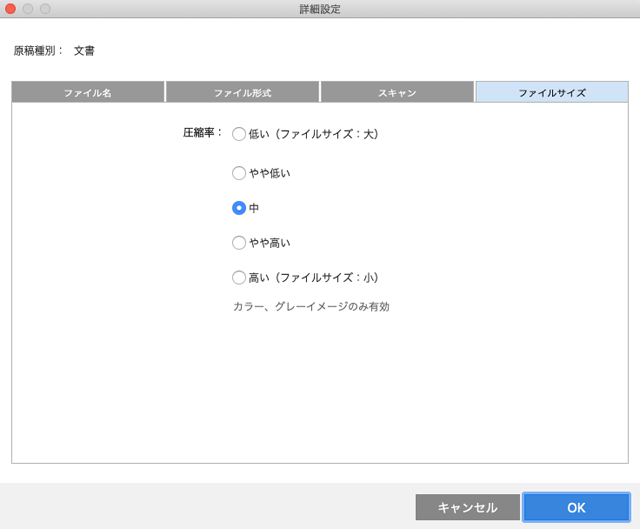
「詳細設定」の「ファイルサイズ」タブ
「OK」をクリックします。
プロファイルを追加
「新規プロファイル追加」の画面の右下の「追加」をクリックし、今作ったスキャン設定を保存します。
スキャンする
「ScanSnap Home」の「Scan」へ進むと元々あったプリセットに並んで先ほど作った自動判別の設定も並んでいるので、それを選んでスキャンします。
iX1500などの機種ならスキャナー本体の液晶画面にも先ほど自分で作った設定が表示されるので、それを選んでスキャンできます。
カラーのペラの文書も、カラーとグレーの混ざった文書も、カラーページとグレースケールのページと文字だけのページが混在した100ページ以上の冊子なども全て先ほど作った自動判別の設定でスキャンすると無難にきれいなPDFになります。
さらに最適な設定でスキャンした場合はお好みで設定を選ぶ
上記で紹介した設定は、仕事などが忙しくてスキャンの設定を毎回選んでいる余裕がなく、また色々な種類の原稿が混在した冊子をスキャンする場合も多いので、仕事なり他の諸活動なりで発生する大量の書類や冊子や私生活のレシートやその他、文書と言えるものは全て同一の設定でスキャンしてしまうための設定です。
ScanSnapには「プロファイル」と名の付いたスキャン設定のプリセットがかなり多数用意されており、設定内容を見るとレシート用ならレシートの記載内容を判別するのに最適な文字認識ができる設定になっているなど、細かく設定が作られています。
ですので、急いでいるわけでもなく、色々な種類の原稿が混在しているわけでもないなら、用途にあった「プロファイル」をその都度選んでスキャンした方が良い結果になるかもしれません。
以上、ScanSnapでカラー文書、グレースケールの文書、文字・線画のみの文書、それらが混在している冊子など、全て自動判別でPDF化する方法の一例でした。

